发布时间:2026-05-28 | 阅读:

线速度和低延迟已经成为生成式 AI(Generative AI)与大语言模型(LLM)全栈基础设施的核心瓶颈。针对 GPU 计算过程中的“数据饥饿”与“内存墙(Memory Wall)”问题,国内内存计算厂商柏睿数据(BorayDATA)推出了基于 GPUDirect Storage (GDS) + SEFS + 100G高性能RoCE网络 的“AI超节点内存池化产品方案”;而在国际上,硅谷顶级高性能数据平台 Weka (WekaFS)则依托其 NeuralMesh架构在 AI 存储领域闻名。两者的底层逻辑都是为了消灭数据搬运路径、让 GPU 满载运行。以下是针对两套方案核心组件及技术实现的彻查与深度对比报告。
一、 核心组件技术解构
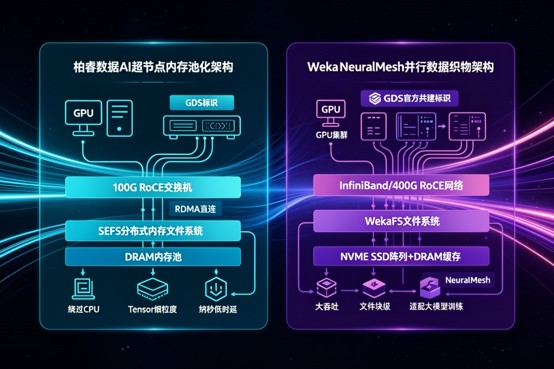
●SEFS(Smart Enterprise File System 分布式内存文件系统):柏睿数据的核心黑科技。它并非传统的磁盘文件系统,而是通过将分布式多节点上的物理 DRAM 内存进行统一虚拟化池化,在逻辑上构建出一个统一可访问的、具备 Linux 标准 POSIX 接口的内存资源池。数据在内存池中以极细粒度(数据流/Tensor级)流动。
●自研 100G 高性能以太网 RoCE 交换机: 柏睿方案在网络层深度融合了自研的100G RoCE(RDMA over Converged Ethernet)网络技术。采用 Spine-Leaf CLOS 拓扑架构,提供端到端、无损(Lossless)、无阻塞、低时延的转发承载网络。利用 RoCE/RDMA 跨节点直接存取内存,彻底 Bypass CPU。
●GPUDirect Storage (GDS) 级联集成: 通过将 SEFS 分布式内存池与 NVIDIA GDS 技术深度绑定,使得计算节点上的 GPU 能够绕过系统主内存与 CPU,直接通过 RoCE 网络向跨节点的“统一内存池”发起高速NVMe-oF/RDMA 级别的读写请求。
●WekaFS (分布式并行文件系统):基于软件定义存储(SDS)架构,同样具备原生 POSIX 接口。Weka 的核心是将高密度本地 NVMe SSD(闪存颗粒)与一部分 DRAM Cache 聚合,虚拟化成一个全球统一的并行高速命名空间。
●NeuralMesh网络亲和力: Weka 自身不研发交换机硬件,但其核心黑科技 NeuralMesh 高度依赖工业界顶级的 InfiniBand(如 NVIDIA Quantum)或 400G 标称 RoCE 网络。它通过定制化的内核态网络驱动与 RDMA 技术,实现存储节点与计算节点(如 DGX SuperPOD)之间的点对点极限吞吐。
|
|
|
|
| 核心存储介质(物理层) |
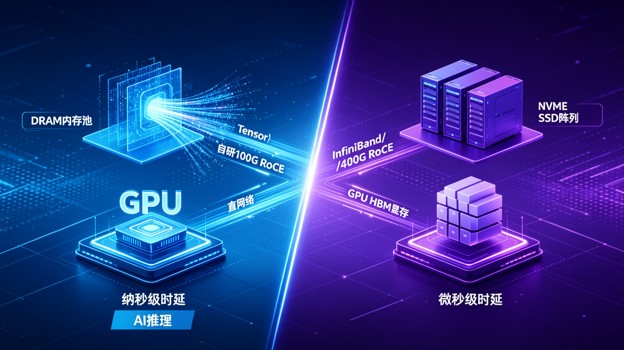
100%纯物理 DRAM 内存构建逻辑上统一的物理内存资源池,时延在纳秒(ns)级。 |
NVMe SSD 固态硬盘 + DRAM 缓存层以高性能闪存颗粒(Flash)为主体,时延在微秒(μs)级。 |
|
|
SEFS (分布式内存文件系统)原生面向内存流设计,数据以流或 Tensor 粒度在内存池中直接寻址,消灭任何磁盘 I/O 软件栈。 |
WekaFS (分布式并行文件系统)原生面向并行硬核大吞吐设计,采用高并发块存储结构,支持超大规模小文件与大文件混合吞吐。 |
|
|
自研 100G 高性能以太网 RoCE 交换机 提供软硬件一体化的定制无损网络,Spine-Leaf 架构,针对全内存池化流量进行专有优化。 |
第三方标准InfiniBand / 400G RoCE 网卡 纯软件定义的 NeuralMesh 织物,完全依赖并释放标准化高端网络硬件的物理吞吐极限。 |
|
|
GPU → RoCE交换机 → SEFS内存池 GPU通过无损RoCE 直接将跨节点 DRAM 数据载入显存,缩短数据搬运路径。 |
GPU → IB/RoCE网络→ NVMe存储网格 GPU通过高效并行链路从 NVMe 闪存阵列中以 TB/s 的吞吐量抽取原始数据集。 |
|
|
流式细粒度(Dataflow / Tensor级) 数据如同“燃料”在内存中无缝流动与共享,极其适合 RAG、KV Cache 等动态计算状态。 |
文件块级 / 大对象级(File / Block级)** 通过极端并行的“大水管”把文件块成批地灌满 GPU HBM 显存缓冲区。 |
|
|
AI推理加速、长上下文(KV Cache)与在线RAG 突破单卡内存限制,提升大模型 Token 吞吐,降低 TTFT(首字响应延迟)响应。 |
大规模 LLM 预训练(Training)与多模态数据摄入 解决千亿参数模型训练期间,海量图片/视频等原始数据集加载及 Checkpoint 极速高并发读写。 |
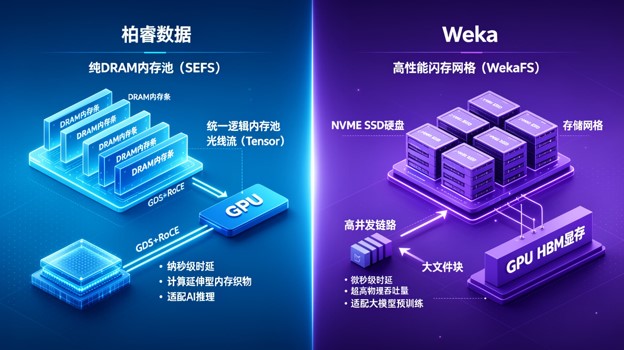
柏睿数据采取了“软硬一体”的垂直整合路线。AI超节点的特征是池化,内存池化对网络丢包极其敏感。柏睿通过**自研的100G高性能以太网RoCE交换机**和 Spine-Leaf CLOS 拓扑,在硬件层确保了网络的端到端无损(Lossless)与零阻塞。这种全栈自研使得 SEFS 文件系统可以和交换机底层队列直接联动,实现感知时间的数据流调度。
相比之下,Weka是一家纯粹的软件定义存储(SDS)厂商。它的 NeuralMesh 是一种运行在通用服务器内核态的软件织物,虽然不研发硬件,但它对第三方网络硬件(如 NVIDIA Quantum Mellanox 交换机)的要求极其严苛。Weka 的优势在于弹性扩展,能够直接利用标准的 400G 顶级InfiniBand 网络跑出每秒数个 TB 的恐怖吞吐,但企业必须承担极高昂的第三方网络硬件采购成本。
这是两者最本质的底层物理物理分野。柏睿 SEFS的核心使命是把分布式节点的内存直接“变成一块大板子”(统一逻辑资源池)。在AI 推理中,GPU 最常遇到的瓶颈是上下文太长、KV Cache 把显存撑爆。SEFS 允许 GPU 绕过本地,直接通过 GDS 和 RoCE 把多余的临时计算状态存到跨节点的统一内存池里。因为物理介质本身就是内存(DRAM 几十ns时延),所以这是一种“计算延伸型内存织物”。
而 Weka尽管有 DRAM Cache,其底层仍然是基于 NVMe SSD 的存储系统。大模型在预训练时需要读写动辄几十个 PB 的原始语料(图像、音视频),训练过程中还需要高频、极其粗暴地写入Checkpoint(检查点归档)以防断电。Weka 并行文件系统的多通道设计能够承受高密度的并发写入和巨大的物理吞吐量,这在磁盘/闪存维度是无可匹敌的,但由于 SSD 固态硬盘本身存在物理延迟(100μs左右),对于亚毫秒级、纳秒级的超高频、精细化大模型状态交互,依然无法完全取代纯物理内存池。
根据真实的 BorayDATA RAG Pipeline 压测数据,柏睿方案表现出极强的“平民化算力赋能”特性。在 360M 文本、173 万条高密语句的测试集下,柏睿全内存分布式向量检索在**完全没有配备 GPU 算力(纯CPU 虚拟机环境)**的情况下,平均查询时间仅需**0.99 秒**。相比之下,传统的单机 GPU 方案(如 FAISS + RTX 3060)虽然 GPU 纯算力极快(0.35秒),但由于数据必须从慢速磁盘加载到内存(21.19秒)再搬运到显存(1.55秒),冷启动综合代价极高。
这意味着,柏睿方案允许企业在没有高阶 GPU(如 A100/H100)的预算下,仅仅通过高性价比的 **CPU + 内存超节点 + 自研RoCE交换机**,就能在中轻量级大模型应用、垂直企业知识库(RAG)和在线特征仓库中实现极速性能。而Weka方案则是一把不折不扣的“重型高精尖武器”,它必须与数百张高端GPU 算力集群绑定才能发挥 NeuralMesh 绕过CPU 的真正物理威力,更适合头部大模型厂商和超算中心。

1.选择 柏睿数据(BorayDATA) AI超节点池化方案: 如果您的核心业务处于 AI 推理端、垂直行业 RAG 落地、大模型长上下文 Token 优化(KV Cache 异构调度)以及实时推荐/风控特征仓库。尤其是当企业希望以最优的资金回报率(ROI)、依托高性价比的物理内存池与自研无损 RoCE 网络构建自动化、热插拔且秒级合规的企业 AI 数据平面时,柏睿方案是工程一体化和推理加速的最佳选择。
2.选择 Weka (NeuralMesh) 方案: 如果您的核心任务是 从零开始预训练百亿、千亿参数级别的多模态大模型,拥有大规模的通用高端 GPU 集群(如 NVIDIA DGX),并且需要每天吞吐数十个 PB 级别的原始非结构化大文件集与极速 Checkpoint 归档,Weka 则是目前国际上最强悍的并行文件存储底座。
010-64700868 400-088-1960
品牌市场:brmarketing@boraydata.com
人才招聘:hr@boraydata.com
北京市朝阳区酒仙桥北路乙十号院

微信视频号

微信公众号
COPYRIGHT ©2014-2025 北京柏睿数据技术股份有限公司京ICP备16005192号隐私协议法律声明
 京公网安备 11010502043838号
京公网安备 11010502043838号


