发布时间:2026-06-12 | 阅读:

在大模型快速发展的今天,决定推理效率的并不只是GPU算力本身,更重要的是GPU能否持续获得数据供给。近期,基于天数智芯BI‑V150平台的测试表明,通过SEFS RoCE内存池设备、叠加PD Firmware优化以及内存预取流水线,可以显著提升国产GPU的实际推理效率。
测试结果显示:Pipeline模式GPU利用率由20%提升至93%;低延迟模式TTFT由3500ms降低至442ms;Pipeline吞吐量由310 tok/s提升至404 tok/s。这些结果说明,数据预取供给路径已经成为影响大模型推理性能的重要因素。
SEFS AI Inference Fabric并非替代GPU,而是通过RoCE内存池存储、SEFS Runtime和Firmware级优化,让数据在GPU需要之前提前到位,减少等待时间,让GPU持续工作。
未来大模型基础设施的竞争,将逐步从单纯的GPU竞争转向Inference Fabric竞争。谁能够更高效地组织数据流、调度Tensor和管理KV Cache,谁就能够产生更多Token并降低推理成本。
此次BI‑V150测试验证了一条重要路径:国产GPU性能提升不仅依赖更大的芯片和更高的功耗,同样可以通过先进的内存数据供给体系获得跨越式提升。
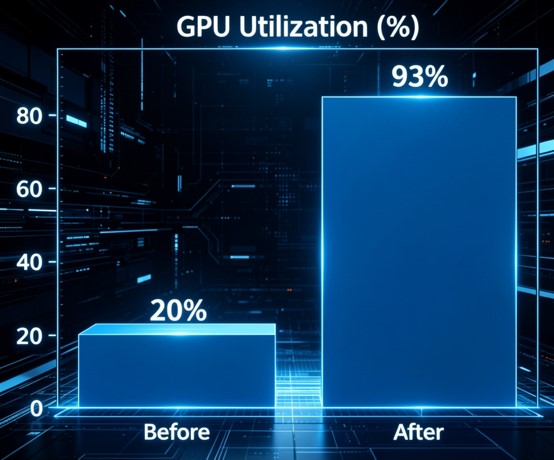
GPU利用率
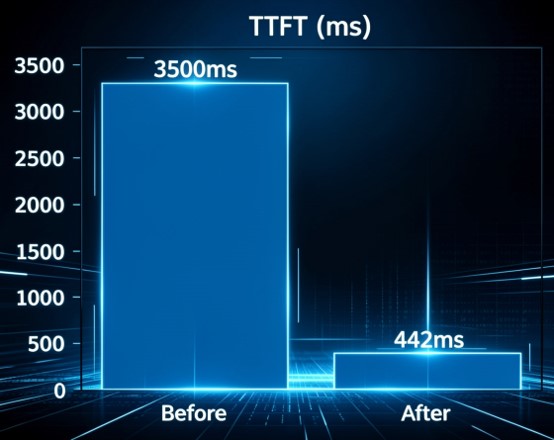
Token 延迟
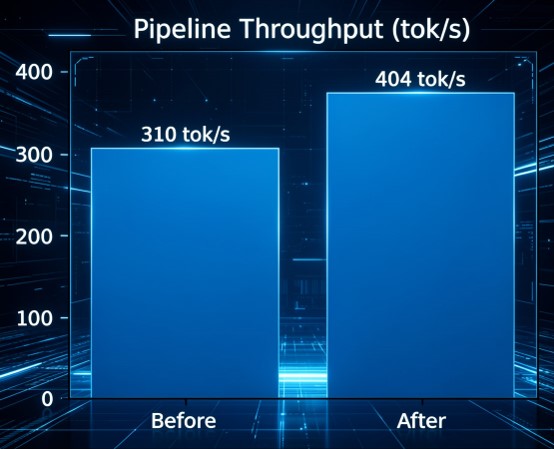
Pipeline吞吐量
010-64700868 400-088-1960
品牌市场:brmarketing@boraydata.com
人才招聘:hr@boraydata.com
北京市朝阳区酒仙桥北路乙十号院

微信视频号

微信公众号
COPYRIGHT ©2014-2025 北京柏睿数据技术股份有限公司京ICP备16005192号隐私协议法律声明
 京公网安备 11010502043838号
京公网安备 11010502043838号


