发布时间:2026-06-02 | 阅读:

"Rapids Tensor Pipeline",重点突出:Distributed Memory File System、RoCE Native AI Runtime、Tensor Streaming、GPU Prefetch、AI Data Plane 与 Weka 差异化竞争力。
 第1页:用户内存池中没有文件
第1页:用户内存池中没有文件
这里展示的是 Rapids Tensor Pipeline 的底层数据平面。用户当前接入的是一个真正的 Distributed Memory Fabric。可以看到,当前用户在全局分布式内存文件系统中还没有任何文件。传统 AI 系统通常依赖 SSD、NAS 或对象存储。但 Rapids 的架构完全不同。我们把 AI 的核心数据层,直接建立在分布式内存池之上。AI 不再等待磁盘 IO,而是直接通过自研 RoCE 网络,从远端内存高速获取 Tensor 数据。未来 AI 推理的瓶颈,已经不是单纯 GPU 算力。而是谁能最快把数据送到 GPU。
第2页:用户登录 Tensor Pipeline
现在用户登录 Rapids Tensor Pipeline。这已经不是传统意义上的 AI 应用登录。用户实际上是在接入整个 AI Data Plane。
后续所有:- 向量索引- Embedding- Tensor 数据- 推理缓存- GPU 数据流都将在分布式内存文件系统中高速流动。
第3页:查询不到内容
当前内存池中没有文件,因此系统无法完成 Tensor 检索。这里真实体现了未来 AI Infra 的核心逻辑:AI 的瓶颈,不只是模型。真正的瓶颈,是数据流。如果数据无法高速进入 GPU,再强大的 GPU 也只能等待。因此 Rapids 的核心不是单纯“存储”,而是:AI Tensor Delivery System。
第4页:开始提问
现在用户开始向 Tensor Pipeline 发起查询。传统系统的数据路径通常是:磁盘 → 网络 → CPU → GPU,整个过程会产生大量 IO、协议与调度开销。而 Rapids 的设计是:文件、索引、Embedding、Tensor 数据,全部直接驻留在 Distributed Memory File System 中。再通过自研 RoCE 网络,实现 GPU 级别的数据高速送达。
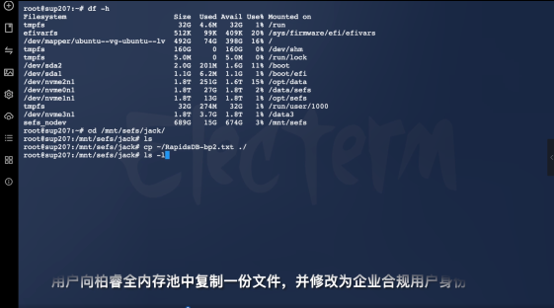
第5页:文件进入分布式内存文件系统
现在用户把文件复制到 SEFS 分布式内存文件系统。这里并不是传统共享存储。而是 AI Native Memory Fabric。文件一旦进入系统,后台就会自动完成:- Tensor 化- 数据切片- 分布式映射- GPU 数据预取准备未来的大模型推理,本质上是 Tensor Streaming。而不是传统文件读取。
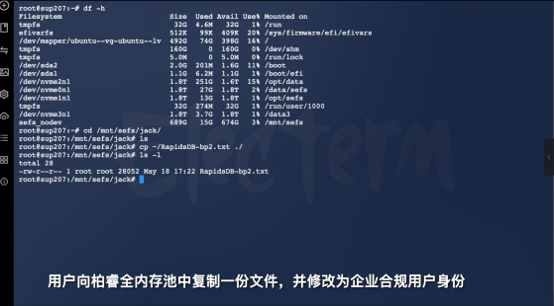 第6页:文件已经进入内存池
第6页:文件已经进入内存池
现在文件已经正式进入分布式内存文件系统。传统 NAS 或对象存储,即使做到高吞吐,依然存在大量协议与 IO 调度开销。
而 Rapids 的目标是:让 AI 数据像内存一样流动。这也是为什么 Rapids 会自研 RoCE 网络。因为未来 AI 推理真正需要的,已经不是传统网络,而是:Memory Native AI Fabric。
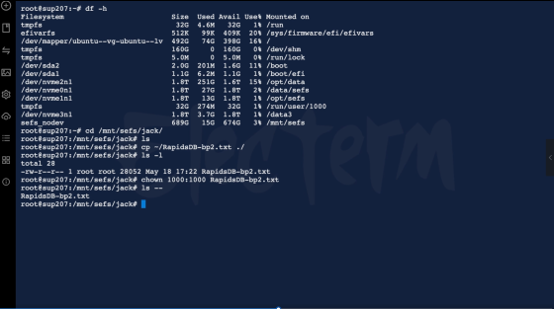
第7页:企业级 AI Data Plane
现在文件已经归属于企业级用户。这意味着:整个系统不仅仅是文件系统。它实际上已经成为:- AI Data Plane- Tensor Runtime Layer- Distributed Memory Fabric- GPU Data Scheduling System未来大量企业 AI 最大的问题并不是 GPU 不够。而是 GPU 大量时间在等待数据。Rapids 的目标,就是让 GPU 永远不等待 Tensor。
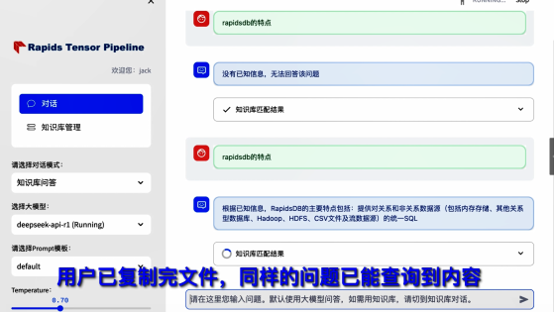
第8页:重新查询内容
现在用户再次发起查询。由于文件已经进入 Distributed Memory File System,系统已经可以高速完成 Tensor 检索与推理。这里真正重要的不是“能查到内容”。而是:数据已经真正进入 AI 推理数据平面。
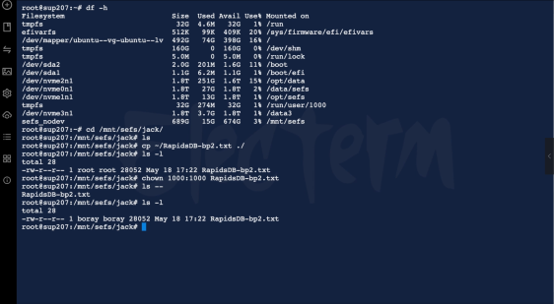
第9页:后台建立 Tensor Mapping
在后台,系统已经自动完成:- 文件切片- Embedding- Tensor Mapping- 向量索引- GPU 数据路径构建这些数据全部驻留在内存池中。这一点与传统 VectorDB 有巨大区别。很多传统方案仍然依赖 SSD Cache。而 Rapids 从第一天开始,就是:Memory Native Architecture。
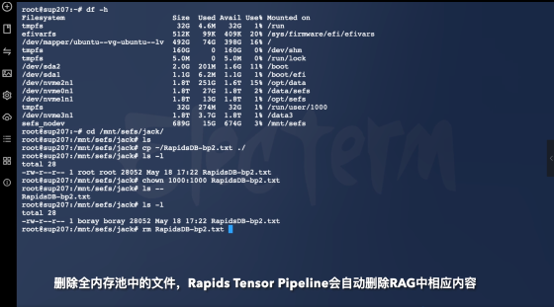
第10页:删除文件
现在用户删除文件。这里展示的不只是删除动作。真正重要的是:整个 Tensor Pipeline 与内存池之间,是实时联动的。文件删除后:- 向量索引- Embedding- Tensor Mapping- GPU 缓存路径,都会同步失效。整个 AI Runtime 已经真正实现:Data Driven Inference。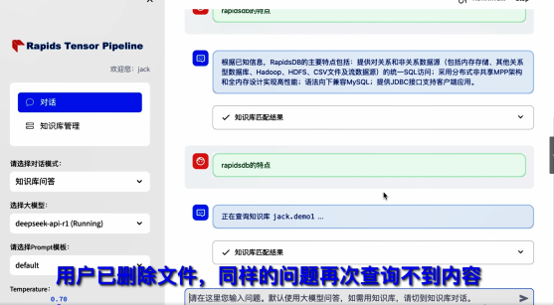
第11页:删除后无法查询
现在,同样的问题已经无法查询到结果。这意味着:AI 推理已经真正建立在实时数据流之上。而不是传统数据库时代的:“静态存储 + 查询模式”。未来 AI 基础设施的核心,一定是:Dynamic Tensor Flow。

第12页:内存池再次为空
现在用户的内存池再次为空。这里体现了一个非常关键的未来方向:AI 基础设施的核心,已经不是磁盘容量。而是:Tensor 数据的高速流动能力。未来真正决定 AI 系统性能的,是 GPU 前面的数据平面。
Rapids Tensor Pipeline 的性能结果。通过:- 全分布式架构- Distributed Memory File System- 自研 RoCE 网络- Tensor Streaming- GPU 数据近端化- AI Data Plane。Rapids 在 AI 检索与推理场景中,相比传统架构实现了数量级性能提升。很多人会把 Rapids 与 Weka 做比较。但 Weka 的核心仍然是:“高速 AI 存储”。而 Rapids 的目标是:AI Data Plane。Weka 的逻辑是:让存储更快。而 Rapids 的逻辑是:让 Tensor 数据直接参与 AI 推理流动。因此 Rapids 不只是文件系统,它更像:- AI Runtime- GPU Data Plane- Tensor Streaming Fabric- Distributed Memory AI Infrastructure。未来真正的大模型基础设施,一定是:Memory Flow Architecture。而这,正是 Rapids Tensor Pipeline 的核心方向。
010-64700868 400-088-1960
品牌市场:brmarketing@boraydata.com
人才招聘:hr@boraydata.com
北京市朝阳区酒仙桥北路乙十号院

微信视频号

微信公众号
COPYRIGHT ©2014-2025 北京柏睿数据技术股份有限公司京ICP备16005192号隐私协议法律声明
 京公网安备 11010502043838号
京公网安备 11010502043838号


